
Category: coding diary
988 Posts

NVMe SSD and sleep
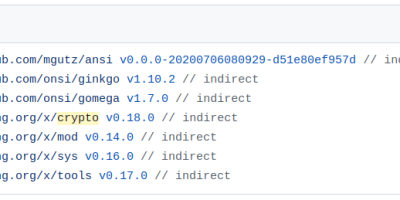
Why does golines need crypto?
Tiling window mangers!

Turning the power button LED off.

Vi(m) it is
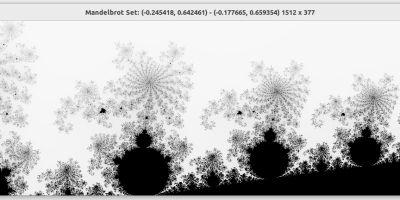
golang (7): parallelization

golang (6): Profiling

4D recap

golang (5): tangled up in slices

coding diary, Life, politics, sociology
Ubuntu on a ThinkPad
golang (4): methods
golang (3): stuff I miss
golang (2): some syntax is better than C++
Learning golang: advent of code (1)

Three dimensional slices of hyper space

A Quest for a Quest 2 example that will compile

Setting up developer tools for Quest 2

best of, coding diary, microcontrollers, statistics, math and science
Counterfeit DS18B20s in action

coding diary, microcontrollers
